
Building Salesforce Flows is a must for every Admin these days, but let’s be honest—nailing it perfectly on the first try? Not always the case. Mistakes are part of the process, and honestly, we believe they’re where some of the best lessons come from.
In many realistic cases—trust us, we’ve asked our own team of [now] Flow pros—it’s not impossible to feel confident when you see some of your first automations start working…that is until you start to see the errors stack up. *cue panic mode*
This experience has taught our team a ton and helped shape the delivery standards we uphold today at Lane Four. The secret? Embrace the hiccups. Each challenge refines best practices and leads to smarter, more efficient solutioning, greatly reducing the risk of functionality and performance issues. Now, let’s explore some of the most common mistakes Salesforce Admins make with Flows.
1. Complex Flow Design or Inefficient Use of Flow Elements
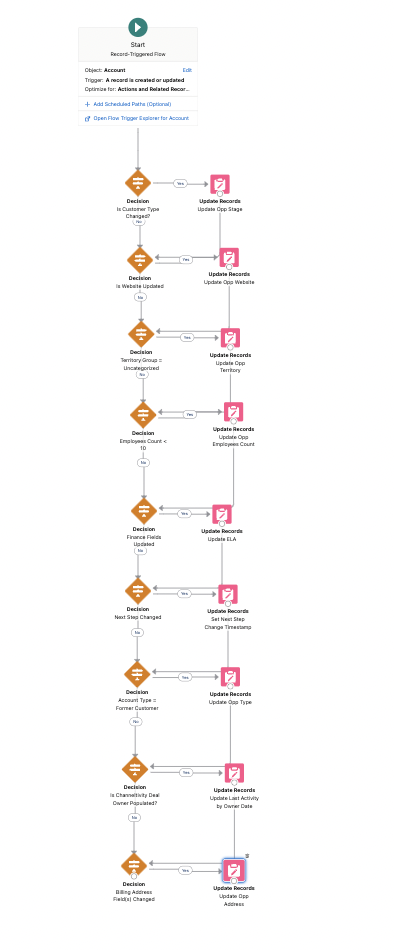
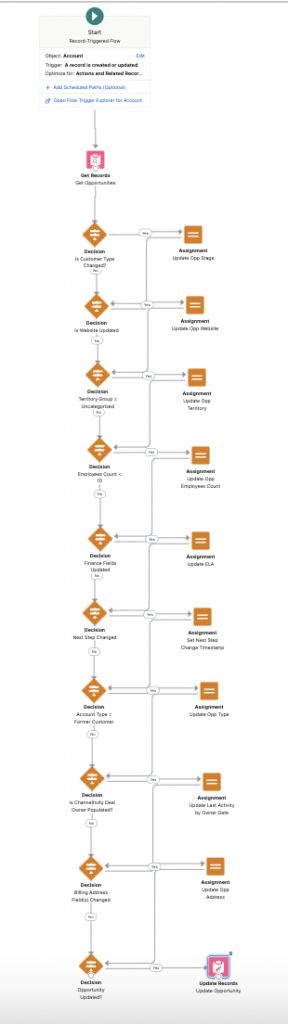
- Details: Building Flows that are overly complex, with too many steps, decision nodes, assignment nodes and conditions. Another misstep? Using multiple decision elements to evaluate conditions that could be grouped together. Also, rebuilding similar logic across multiple flows instead of using Subflows.
- Impact: Overcomplicating your Flow not only makes it harder to navigate and analyze but also slows down performance. The more cluttered your Flow is, the longer it takes to process, and the harder it becomes to troubleshoot or maintain down the line. Plus, who wants to dig through a tangled mess every time an update is needed? Keep it simple to save yourself future headaches.
“Less is always more with Flows”
Anthony Mottola, Junior Solutions Architect at Lane Four

2. Using Too Many Pink Nodes
- Details: The use of too many pink nodes such as “Update Records” node instead of Assignment Nodes with one pink node at the end of the Flow to update an Object. Additionally, it’s not ideal to have the pink node consistently trigger on every “Account Update” in the final version of the Flow.
- Impact: Using many pink nodes may lead to exceeding limits and can cause Flows to fail unexpectedly. Database calls are slow when many pink nodes are used and this adds to processing time in addition to limits.
3. Not Handling Errors Properly
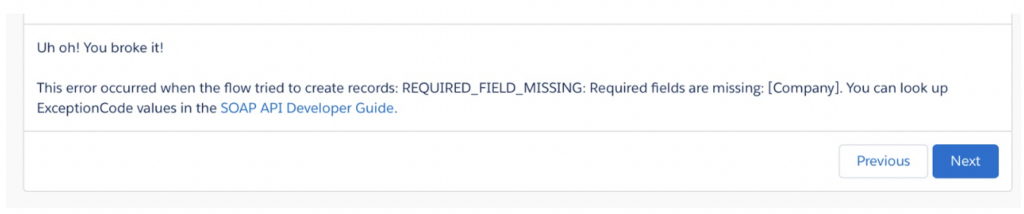
- Details: Failing to implement error handling mechanisms in Flows such as the custom error element. While these errors can help catch validation rule issues, it’s a good practice to go a step further by including helpful information for users, such as an error message with clear instructions or contact details for support. Adding an email or point of contact for troubleshooting can greatly improve the user experience, ensuring issues are addressed quickly and efficiently.
- Impact: It’s crucial to provide users with helpful error messages. Without proper error handling, they’re left staring at vague, generic messages that only add to the confusion. This is not only frustrating, but also makes it harder for admins to figure out what’s actually broken. Implementing clear error handling saves time, improves the user experience, and keeps everyone in the loop when something needs fixing.

4. Not Testing with Multiple Data Sets
- Details: Only testing Flows with a single or limited set of records. Be sure to test across a variety of data sets to ensure existing processes continue functioning smoothly. Admins often make changes that inadvertently break unrelated parts of the system, so thorough testing helps catch these hidden problems before they cause bigger headaches.
- Impact: While your Flow might work perfectly with a small, controlled dataset, real-world scenarios often throw unexpected variables at you. If you’re not testing with a variety of records, you risk your Flow misbehaving when it’s run with different types of data. This could lead to unpredictable results and critical errors. Always test with multiple datasets to cover all your bases and avoid unpleasant surprises.
5. Not Testing in Sandbox and in Production after Deploying
- Details: Deploying Flows directly to Production without adequate testing in Sandbox and Deploying Flows from Sandbox to Production and failing to run tests in Production. If you utilize Flow Tests correctly, it’s actually easier to test in Production post-deployment.
- Impact: Testing in the Sandbox is a must, but it’s not the finish line. Live environments often behave differently from controlled test settings, so if you don’t follow through with post-deployment tests in Production, you’re setting you can be setting yourself up for bad outcomes. A Flow that works in Sandbox might fail in Production, affecting critical business processes and user experiences. Always run thorough tests in both environments to ensure smooth operation.
*For more resources on Testing, check out these articles:
- Kicking Off A New QA Series: Getting Started with Testing!
- QA Series: Understanding Testing Types for Functionality and Performance
- QA Series: Retesting and Regression Testing…What’s the Difference?
- An Intro to Flows Tests: What, Why and Some Considerations
- Salesforce Flows Tests: Creation and Configurations
- Salesforce Flow Tests: 5 Scenarios Where Apex Unit Tests Are the Better Choice
- Salesforce Flow Tests: Deploying with Confidence
- Salesforce Flow Test Limitations → Coming Soon!
6. Improper Labelling and Documenting of Flow Nodes and Versions
- Details: Neglecting to properly label and add descriptions or documentation to your Flow nodes (e.g., Decision, Assignment, Loop, Create Record) and failing to track different Flow versions after saving.
- Impact: Trying to debug or update a Flow that’s poorly labeled can be like navigating a maze with no map. This lack of documentation creates confusion and wastes valuable time. If other admins or developers need to step in, they’ll struggle to understand the Flow’s structure and logic. Proper labeling and version tracking make your Flows easier to maintain, troubleshoot, and scale.
7. Not Keeping Flows Updated
- Details: Failing to update Flows as Salesforce releases new features or as your business processes evolve can lead to outdated automations that miss out on valuable improvements.
- Impact: Over time, this can result in inefficient performance, missed opportunities to leverage new capabilities, and Flows that no longer align with current business needs. Keeping your Flows up-to-date ensures they remain optimized, relevant, and fully functional as both your tech stack and business grow.
8. Missing Entry Criteria
- Details: Not defining proper entry criteria for record-triggered Flows can cause them to fire unnecessarily, activating under the wrong conditions. Proper decision entry criteria ensure Flows are only triggered when truly needed, keeping your system efficient and reliable.
- Impact: When Flows run outside their intended scope, it can lead to significant performance issues by consuming unnecessary system resources. Worse, incorrect data updates or changes may occur, which can disrupt business processes, cause data integrity issues, and lead to user frustration.
To enhance your Flow design, one of our key best practices is following the two-Flow strategy, aiming to have only two Flows per object without entry criteria. This means ensuring your decision criteria comprehensively cover all possible scenarios. It’s not uncommon for beginner admins to overlook certain aspects of a process, resulting in improper decision criteria. This can either allow an automation to fire when it shouldn’t or, conversely, prevent it from triggering when it should. These issues are precisely what thorough testing can help catch, underscoring the importance of robust decision-making criteria in your Flows.
Quick note about Lane Four’s two-Flow strategy recommendation:
At Lane Four, we recommend a “two record-triggered Flows per object” strategy: one before-save Flow and one after-save Flow per object. These are built with the following properties:
- They run on both record creation and update.
- Decision nodes split up processes and ensure they are only triggered when necessary.
- In after-save Flows, record variables are used to store updated records or records to create, and consolidated DML operations are performed on these record variables at the end of the Flow.
We advocate this approach for several reasons:
- Visibility: All Flow elements on an object are visible on the same Flow canvas.
- Quick Debugging: Debugging is faster since you only need to review two Flows.
- Efficiency: For organizations not using Enterprise or higher licenses, this strategy helps avoid hitting the limit on the number of allowed Flows.
- Database Optimization: It can help avoid database query limits, as DML operations on individual objects can be performed once.
- Consistency: It encourages both client admins and our consultants to adopt a consistent and tested approach to Flow design.
- Alignment: This strategy matches the before- and after-save trigger framework of Apex code.
9. Not Connecting Decision & Assignment Lines Appropriately
- Details: When decision or assignment lines aren’t connected properly to the subsequent nodes, the automation gets disrupted and won’t run through the entire Flow as designed.
- Impact: This oversight will prevent the Flow from functioning as intended. The Flow will end prematurely, leaving processes incomplete and causing key actions to be skipped. This can result in missed updates and/or faulty automation, requiring additional troubleshooting and rework.
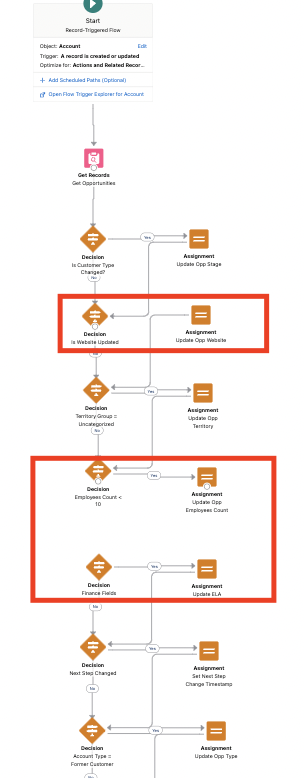
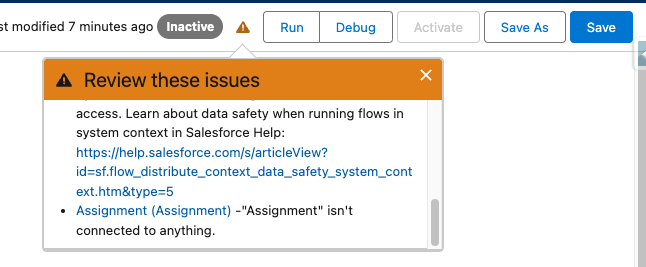
taken care of any connection issues!
10. Using the Wrong Type of Flow
- Details: Choosing the wrong type of Flow, such as using an After-save Flow when a Before-save Flow would be more appropriate (or vice versa), can again, lead to inefficient and ineffective automation. Additionally—and this is crucial—using a Flow in situations where it’s not the best fit can have a significant impact.
Again, another important aspect to consider is using the right elements within your Flow. For example, if you’re building a Before-save Flow, there’s no need to use the Update Records node to update the triggering record; instead, you can simply utilize an Assignment. - Impact: When the wrong Flow type is used, it can cause slower performance by triggering unnecessary database operations (DML), leading to longer processing times. This inefficiency can also create data integrity issues, with incorrect or incomplete data being saved, potentially requiring manual intervention and cleanup later. By selecting the correct Flow type for each automation, you ensure optimal performance and avoid any costly issues.
Building effective Salesforce Flows has its challenges, but those hurdles are where the real growth happens. By steering clear of common mistakes—like overcomplicating designs or skipping proper testing—you can avoid unnecessary headaches and rather, ensure smoother performance with more efficient, maintainable, and scalable Flows. Eager to learn more about how to optimize your team’s automations? Let’s Chat.

Co-Authored by William Amui
Salesforce Administrator at Lane Four
Let's chat!
