
Data is flowing faster than ever before, and it’s only accelerating. With so much data at our fingertips, companies face a critical challenge: how to unify and leverage this information effectively. Yet, it’s not just about collecting data; it’s about building something meaningful with it, like seamless, personalized customer experiences. That’s where Salesforce Data Cloud steps in, offering a solution designed to harness this massive data landscape and transform it into actionable insights. This “unification” process, as it’s known, organizes data based on the individual or company it relates to, bringing valuable insights and richer segmentation capabilities.
While most Salesforce Clouds—think Sales Cloud, Service Cloud, Health Cloud, and other Salesforce industry clouds—share a common core platform and Oracle-based database, Data Cloud takes a different route. Leveraging many integration options and an Apache Parquet based storage layer powered by services like Amazon DynamoDB for real-time data, Amazon S3 for cold storage, and a SQL-based metadata store, Data Cloud achieves this architecture, which allows Data Cloud to deliver petabyte-scale data storage, overcoming the scalability and performance limits typically seen with relational databases.
What Data Cloud is NOT
It is not a middleware tool…
If the ONLY goal is to get data into Salesforce Core, Data Cloud is not the solution.
It is not intended to be the System of Record (or “Source of Truth”). It is a System of Reference.
It should support decision making and strategy, not to track billing records.
At its core, Data Cloud relies on three primary data model objects, which lay the groundwork for everything from data ingestion and harmonization to activation. These core objects form the bedrock of Data Cloud’s unique data handling capabilities, making it a powerhouse for companies looking to unlock the full potential of customer data across the board. But just before we get into more details about these three objects, let’s talk more about how Data Cloud stores data differently.
A Different Take on How Data Is Being Stored
As we noted earlier, Data Cloud isn’t playing by the same rules as the “core” products like Sales Cloud and Service Cloud and uses a very different architecture and tech stack from other Salesforce ‘Clouds’. Instead, it operates on a cutting-edge “Data Lakehouse” architecture. With all data being stored in a data lakehouse using the Parquet file format within S3 buckets, unlike the row-oriented CSV format, Apache Parquet uses a columnar storage model that is specifically optimized and designed for managing vast and complex datasets.
To add another layer of sophistication, Data Cloud uses Apache Iceberg as an abstraction layer, bridging the physical data files and their organization into coherent tables. This setup allows for seamless integration with powerful data processing frameworks like Apache Spark and Apache Presto, as well as high-performance querying through services like Amazon Athena and Amazon EMR. Together, these technologies enable efficient record-level updates and SQL queries, making Data Cloud a robust solution for modern data management. Before we come back to the key object models, let’s talk use cases.
Practical Applications: Data Cloud Use Cases
Curious about how you can leverage Data Cloud for your specific needs? Here are some practical use cases:
- View-Only Insights from External Systems: Provide Salesforce users with insight into data from an external system while restricting edit access. For instance, if a customer has signed up for all your webinars, this information can be displayed in their profile without allowing modifications.
- Customer Segmentation for Marketing: Facilitate precise customer segmentation to enhance marketing strategies. By utilizing Data Cloud, businesses can better understand their customer base and tailor campaigns accordingly.
- Storage of Legacy Records: Store “legacy” records that are related to accounts and contacts but aren’t actively being managed. This approach optimizes query performance and storage limits while maintaining the ability to easily reactivate these records if needed.
- Partial Sync Between Salesforce Orgs: Enable a partial sync between two Salesforce orgs where data cannot be written to the opposite org. This allows for effective data sharing without compromising data integrity or security.

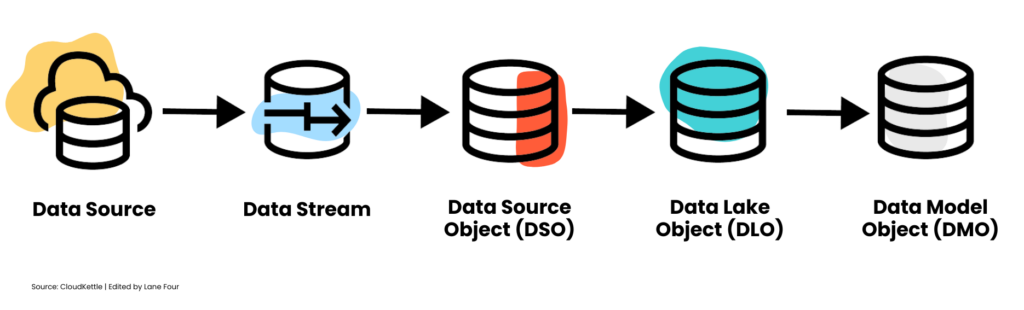
The 3 Key Data Model Objects in Data Cloud

Model 1: Data Source Object (DSO) → The Original Format
Data Source Object (DSO) is where your data streams are first ingested. Think of the DSO as a temporary staging area—it holds your data in its raw, native file format (like a CSV) until it’s ready for the next steps.
Model 2: Data Lake Object (DLO) → The Transformed Data
Next up is the Data Lake Object (DLO which serves as the first point of inspection in your data flow. Here, users can prepare their data by mapping fields and applying more in-depth transformations. Just like the DSO, the DLO provides a physical storage solution, but it’s specifically designed for the output of a DSO and any transformations applied.
DLOs are typed, schema-based, materialized views stored in Amazon S3 as Apache Parquet files—a column-oriented file format optimized for efficient data storage and retrieval as we mentioned earlier. Remember that abstraction layer? This is also where Apache Iceberg sits—between the physical data files and their table representation, enhancing usability. Using industry-standard formats that are widely compatible with other cloud platforms enables architects to build features like live query functionality, allowing other data lakes, such as Snowflake, to query data within DMOs without needing to move or duplicate it.
Model 3: Data Model Object (DMO) → The Virtual Representation
Finally, we have the Data Model Object (DMO), which offers a virtual, non-materialized view into the data lake. Unlike DSOs and DLOs that use a physical data store, DMOs provide dynamic access to the most current data snapshot in the DLOs without actually storing it.
Attributes within a DMO can be derived from various Data Streams, Calculated Insights, and other sources, creating a flexible and comprehensive view.
While DMOs don’t classify data streams by category directly, they inherit categories from the first DLO mapped to them. Once a DMO has adopted a category, only DLOs of that same category can connect with it.
The shape of DMOs is very similar to Salesforce objects that you are likely familiar with (ie Accounts, Contacts, etc.). Following the same {namespace}__{fieldname}__c pattern that anyone who’s worked with Salesforce data previously is used to.
Much like other Salesforce objects, DMOs establish a canonical data model with predefined attributes presented as standard objects. But they also allow for customization, as you can create custom DMOs—you can think of them as custom objects. DMOs can have standard or custom relationships with other DMOs, structured as one-to-one or many-to-one relationships. Currently, there are 89 standard DMOs in Data Cloud, with more on the way to support diverse entity use cases.
These DMOs are organized into various subject areas, including:
- Case: For service and support interactions.
- Engagement: To track individual engagement activities, like email sends, opens, and clicks.
- Loyalty: For managing reward and recognition programs.
- Party: To represent individual attributes such as contact or account information.
- Privacy: For monitoring data privacy preferences and consent.
- Product: To define attributes related to products and services.
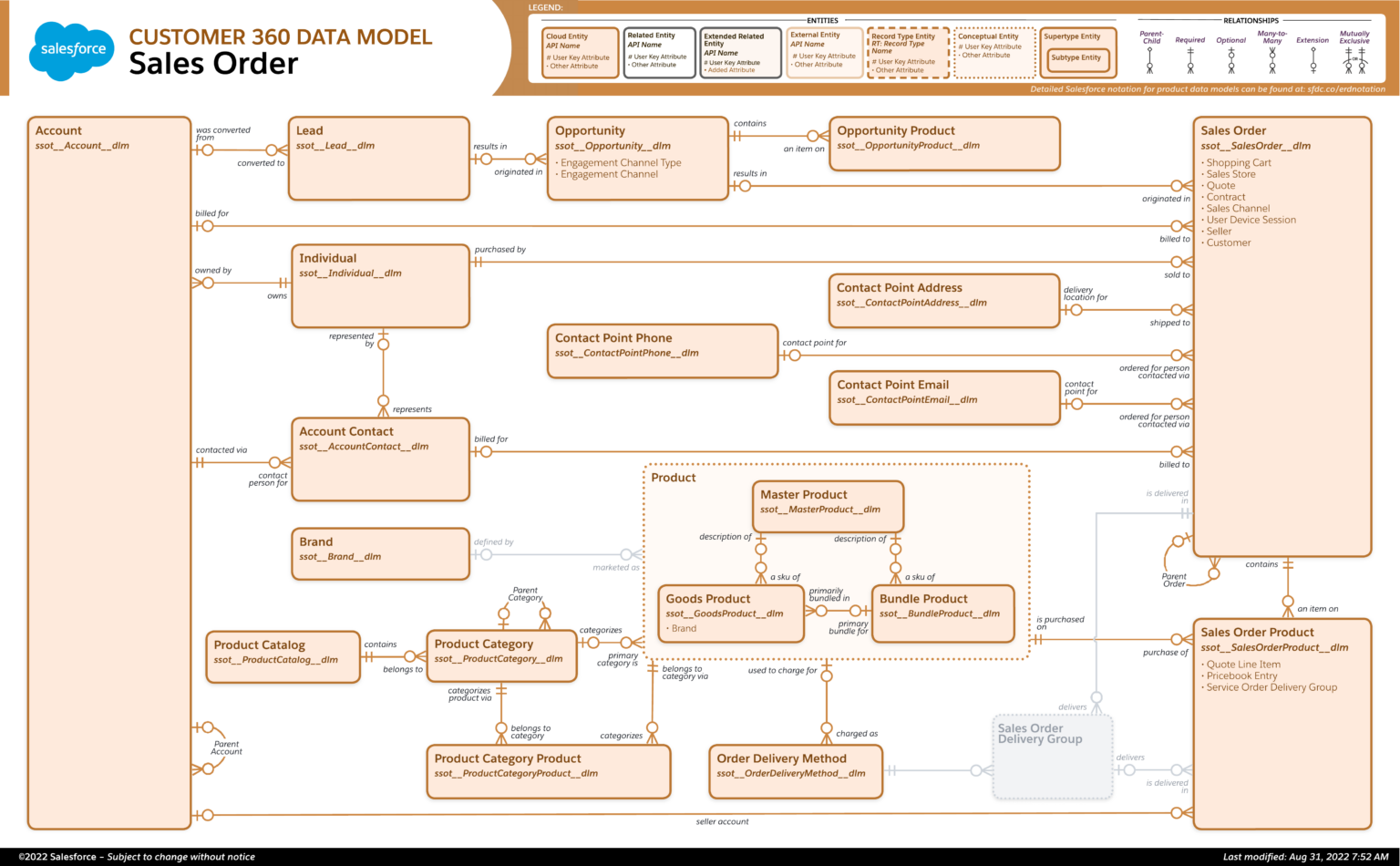
- Sales Order: For detailing past and forecast sales by product.
A few other important things to note: You can leverage Flows and SOQL with Data Cloud Objects, giving you control over what data gets returned to your “Core” database and what stays in the Data Cloud. This flexibility allows you to optimize your data flow and storage efficiently. Additionally, we also want to point out that Data Cloud operates on a usage-based pricing model, making it especially important to design processes with efficiency in mind to manage costs effectively.
We’re in an era where data flows at an unprecedented rate, and Salesforce estimates that by 2025, there will be 100ZB of data in the cloud. Yes, that’s zattabytes. That’s 100 trillion gigabytes, just sitting across various systems, waiting to be put to use. To transform this data into something meaningful—like exceptional customer experiences—companies need a way to harness and unify it effectively.
Salesforce Data Cloud offers a solution that can finally keep pace with today’s massive, diverse data requirements. By organizing, unifying, and storing customer data at scale, Data Cloud empowers businesses to capture a true 360-degree view of every interaction. This capability isn’t just about better data storage; it’s about enabling smarter, more personalized engagement across channels. Until now, Data Cloud’s been largely seen as a way to unify data—a bridge for connecting information from multiple sources. Will this role evolve within the Salesforce context? Perhaps, though we think it may be too early to say for certain. What’s clear is that Data Cloud opens up new possibilities, and the best way forward is to keep learning, stay curious, and continue to share what we discover. We hope this article offers some clarity on what Data Cloud can achieve today.
As Salesforce continues to innovate, Data Cloud stands ready to support businesses in harnessing data more effectively and strategically for years to come. Ready to learn how Data Cloud can transform your data approach? Let’s chat.
Let's chat!

